




Contents
- Quick Summary:
- What is data synchronization?
- Types of data synchronization
- One-way synchronization
- Two-way synchronization
- Multi-way synchronization
- Hybrid synchronization
- Real-time data synchronization
- Batch data synchronization
- Data synchronization dynamics
- Schema drift
- API throttling
- Retry storms
- Event duplication
- Partial synchronization
- Data synchronization methods
- Polling-based synchronization
- Webhook synchronization
- Change data capture
- Streaming and event-driven synchronization
- What Is Real-time Data Synchronization?
- Real-time vs. Near-real-time vs. Batch Synchronization
- How Real-time Data Sync Works: Event-driven vs. Polling
- Event-driven synchronization
- Polling-based synchronization
- Types of Real-time Data Synchronization
- Database-to-database synchronization
- Application synchronization
- File synchronization
- Cloud synchronization
- Data synchronization, replication and integration
- Data synchronization vs replication vs integration
- Why Is Real-time Data Synchronization Important?
- Practical Real-time Data Synchronization Use Cases
- WooCommerce inventory synchronization
- SaaS billing platforms
- AI automation workflows
- Challenges of Syncing Data in Real-time
- Optimizing data synchronization tools
- Best practices for data synchronization
- Define an authoritative source
- Use queues everywhere
- Track synchronization state
- Build for retries
- Add observability early
- Key features to look for in a data sync platform
- How to Choose the Right Real-time Data Synchronization Tool
- Benefits of data synchronization
- Frequently Asked Questions
- What is database synchronization?
- What is real time data synchronization?
- How to check database synchronization status in SQL Server?
- What are the best tools for real time data synchronization?
- What causes synchronization failures?
- Is bidirectional database synchronization risky?
- Conclusion
Inventory says 12 units in WooCommerce. ERP shows 4. The warehouse already shipped 3 more orders. Customer support refunds an item that accounting still considers paid.
This is what broken synchronization looks like in production.
Most growing platforms do not fail because databases cannot store data. They fail because systems stop agreeing with each other. The CRM, payment gateway, warehouse platform, analytics stack, SaaS integrations, mobile apps, and operational dashboards drift apart over time.
That drift creates operational debt:
- duplicate records
- stale inventory
- delayed reporting
- webhook failures
- reconciliation overhead
- customer-facing inconsistencies
- SLA violations
Real time data synchronization solves that problem when implemented correctly. Not through generic syncing plugins or scheduled cron jobs, but through event-driven architecture, resilient queues, change data capture pipelines, and properly designed synchronization workflows.
The challenge is that most synchronization systems work in staging environments but fail under production load.
Quick Summary:
- Real time data synchronization reduces operational lag between connected systems and minimizes data freshness gaps.
- Polling-based synchronization becomes expensive and unreliable at scale compared to event-driven synchronization.
- Database synchronization requires conflict resolution, retry logic, idempotency, observability, and schema governance.
- WooCommerce and WordPress synchronization commonly fail due to plugin conflicts, slow cron execution, and poor queue handling.
- CDC pipelines, message queues, Redis caching, and webhook orchestration are standard components in scalable sync architecture.
- Businesses outgrow off-the-shelf synchronization tools once multi-system workflows and operational complexity increase.
What is data synchronization?
Data synchronization is the process of keeping data records consistent across multiple connected systems.
A source system pushes inserts, updates, deletions, or change events to one or more target systems while preserving data accuracy and consistency.
Typical synchronization flows include:
- CRM synchronization with ERP systems
- WooCommerce inventory synchronization with warehouse software
- SaaS application synchronization with billing systems
- SQL database synchronization across regions
- cloud synchronization between distributed environments
- reporting consolidation into data warehouses
The main goal is maintaining a reliable source of truth while minimizing latency between systems.
A synchronization system typically includes:
- APIs
- event streams
- queues
- webhook synchronization
- retry mechanisms
- schema mapping
- validation layers
- conflict resolution logic
- audit trails
Without these controls, synchronization eventually produces duplicate records, missed updates, or data corruption.
Types of data synchronization
Different systems require different synchronization models.
One-way synchronization
One authoritative source pushes data to downstream systems.
Example:
- ERP → WooCommerce product catalog
- HR system → payroll platform
This is simpler operationally because ownership is clear.
Two-way synchronization
Both systems can modify records.
Example:
- CRM and support platform
- mobile app and backend platform
Bidirectional database synchronization introduces conflict resolution challenges quickly.
Multi-way synchronization
Multiple systems exchange updates simultaneously.
Example:
- marketplace platforms
- omnichannel commerce systems
- multi-region SaaS platforms
This requires event ordering, distributed locking strategies, and synchronization metadata tracking.
Hybrid synchronization
A mix of batch synchronization and real-time updates.
This is common in enterprise environments where legacy systems cannot support streaming synchronization.
Real-time data synchronization
Real-time data synchronization propagates updates immediately after a change event occurs.
Instead of waiting for scheduled jobs, systems react continuously.
Typical triggers include:
- database writes
- webhook events
- API callbacks
- queue messages
- CDC streams
- user actions
A real-time database synchronization workflow often looks like this:
- User updates inventory in WooCommerce
- Database transaction commits
- Change event enters queue
- Worker validates payload
- ERP API receives update
- Redis cache invalidates stale records
- Analytics pipeline receives event stream
- Monitoring system logs synchronization state
Under production load, every step matters.
The architecture fails if:
- queues back up
- API rate limits trigger throttling
- retries duplicate records
- workers process out-of-order events
- schema drift breaks field mapping
This is why real time data synchronization is more of an operational engineering problem than a plugin installation task.
Batch data synchronization
Batch synchronization processes updates at scheduled intervals.
Typical intervals:
- every 5 minutes
- hourly
- nightly ETL jobs
Batch synchronization still works well for:
- reporting systems
- financial reconciliation
- archival systems
- low-priority analytics
- large data migration workloads
The downside is obvious under operational pressure.
Inventory, subscriptions, payments, refunds, and customer activity cannot tolerate large freshness gaps.
Data synchronization dynamics
Synchronization becomes harder as systems evolve.
The operational complexity grows because:
- schemas change
- APIs version differently
- teams modify business rules
- integrations multiply
- data transformation requirements expand
A simple synchronization process eventually becomes a distributed coordination problem.
Common failure patterns include:
Schema drift
One platform changes field structures without updating downstream systems.
API throttling
SaaS applications impose API rate limits that delay synchronization pipelines.
Retry storms
Poor retry logic overwhelms downstream infrastructure after outages.
Event duplication
Without idempotency controls, retries create duplicate records.
Partial synchronization
One system updates successfully while another fails silently.
This is why mature data sync platforms prioritize observability and audit logging heavily.
Data synchronization methods
Polling-based synchronization
The system repeatedly checks for updates.
Simple to implement but inefficient at scale.
Problems include:
- high API usage
- delayed updates
- unnecessary database load
- poor scalability
Polling is common in legacy WordPress integrations because many plugins lack event-driven support.
Webhook synchronization
Systems push updates immediately through callbacks.
This reduces latency significantly.
However, webhook systems require:
- signature validation
- replay protection
- dead-letter queues
- retry orchestration
- observability
Webhook reliability becomes critical for payment systems and WooCommerce synchronization.
Change data capture
Change data capture (CDC) monitors database transaction logs directly.
CDC is widely used for:
- sql server database synchronization
- mysql database synchronization
- postgresql replication pipelines
- analytics streaming
Instead of querying tables repeatedly, CDC streams changes efficiently.
Popular CDC technologies include:
- Debezium
- Kafka Connect
- AWS DMS
For reference on CDC architecture, this overview of Change Data Capture provides a useful technical baseline. CDC is one of the most reliable approaches for real-time database synchronization.
It works by capturing insert synchronization, update synchronization, and delete events directly from database transaction logs.
Advantages:
- minimal query overhead
- low latency
- high consistency
- scalable streaming pipelines
Challenges:
- operational complexity
- infrastructure management
- event ordering
- replay handling
- schema evolution
CDC pipelines often outperform direct API synchronization in enterprise systems because databases remain the authoritative source.
Streaming and event-driven synchronization
Modern distributed database synchronization increasingly relies on event-driven architecture.
Typical stack:
- Kafka or RabbitMQ
- Redis streams
- async workers
- webhook processors
- stream consumers
Instead of direct synchronous API calls, systems publish events asynchronously.
Benefits include:
- lower coupling
- better resilience
- retry isolation
- horizontal scaling
- reduced request latency
A real-time database synchronization Redis layer is commonly used for:
- transient synchronization state
- queue buffering
- cache invalidation
- distributed locking
Redis itself is not the synchronization engine. It is usually part of a broader orchestration layer.
What Is Real-time Data Synchronization?
Real-time data synchronization continuously propagates changes between systems with minimal delay.
The difference between real-time and traditional synchronization is not just speed. It is architectural behavior.
A true real-time data sync platform must support:
- event propagation
- near-instant updates
- transactional consistency
- retry orchestration
- observability
- fault tolerance
A cron-based sync every minute is not truly real-time synchronization.
Real-time vs. Near-real-time vs. Batch Synchronization
| Method | Typical Delay | Best Use Case |
|---|---|---|
| Real-time synchronization | milliseconds to seconds | payments, inventory, subscriptions |
| Near-real-time synchronization | seconds to minutes | dashboards, analytics |
| Batch synchronization | minutes to hours | reporting, archival |
Trying to force every workflow into real-time synchronization usually increases infrastructure cost unnecessarily.
Operational priorities matter more than theoretical speed.
How Real-time Data Sync Works: Event-driven vs. Polling
Production-grade synchronization often depends on stable webhook orchestration, queue processing, and properly engineered API integration services that can handle retries, throttling, and distributed workflows reliably.
Event-driven synchronization
A change event triggers synchronization instantly.
Better for:
- enterprise data sync
- SaaS integration
- WooCommerce synchronization
- distributed systems
Polling-based synchronization
Systems repeatedly request updates.
Better for:
- legacy platforms
- low-frequency updates
- constrained integrations
At scale, event-driven systems usually become more maintainable despite higher initial complexity.
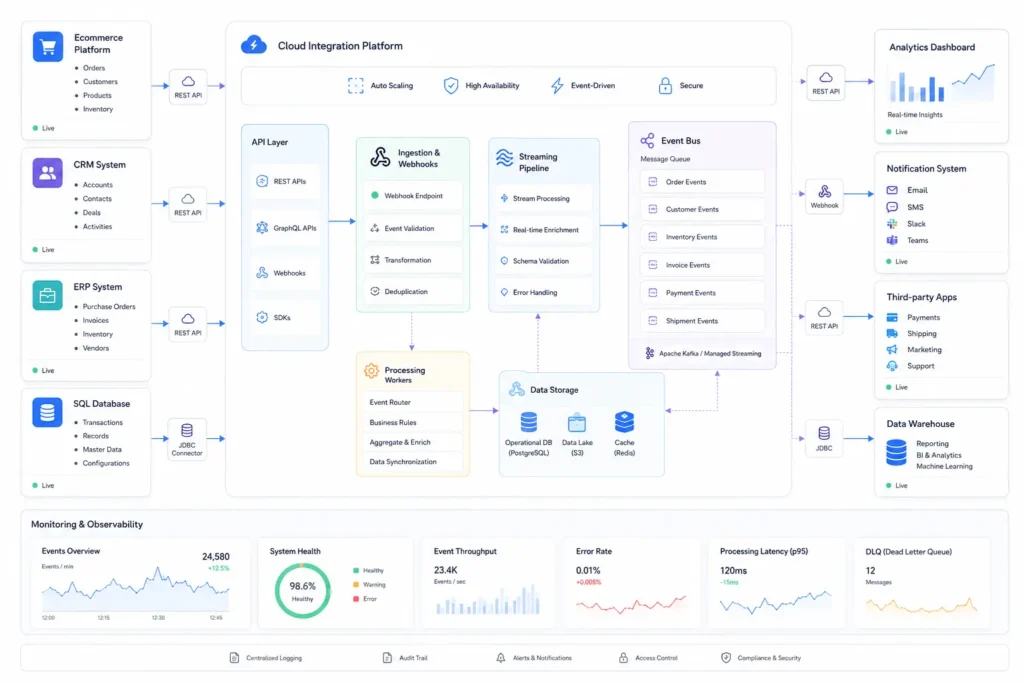
Types of Real-time Data Synchronization
Database-to-database synchronization
Used for:
- sql database synchronization
- mysql database synchronization tools
- oracle database synchronization tools
- postgresql database synchronization tool deployments
Application synchronization
Examples include:
- CRM synchronization
- ERP synchronization
- SaaS applications
- support platforms
File synchronization
Common in media-heavy workflows and distributed storage systems.
Cloud synchronization
Frequently used in multi-region infrastructure and cloud-native applications.
Data synchronization, replication and integration
These terms overlap but are not identical.
| Concept | Primary Goal |
|---|---|
| Data synchronization | maintain consistency |
| Data replication | duplicate data availability |
| Data integration | combine systems and workflows |
Database replication often copies data passively.
Synchronization includes logic, validation, and operational workflows.
Integration focuses more on business process coordination.
Data synchronization vs replication vs integration
Many teams confuse replication with synchronization.
A replicated database can still contain stale business logic if downstream systems fail to process updates correctly.
Similarly, an integration platform can move data while still lacking consistency guarantees.
Production-grade synchronization requires:
- synchronization rules
- conflict resolution
- validation
- monitoring
- retry handling
- operational observability
Why Is Real-time Data Synchronization Important?
The operational impact becomes obvious once platforms scale.
Real-time updates improve:
- customer experience
- reporting accuracy
- operational efficiency
- fraud prevention
- inventory consistency
- subscription management
- SLA compliance
For WooCommerce and marketplace systems, synchronization delays directly affect revenue.
Overselling inventory is usually a synchronization problem, not an ecommerce problem.
Practical Real-time Data Synchronization Use Cases
High-volume ecommerce brands running multi-channel inventory, fulfillment automation, and ERP synchronization often require custom middleware and custom Shopify development services once native app integrations start creating operational bottlenecks.
WooCommerce inventory synchronization
WooCommerce stores often synchronize with:
- ERPs
- warehouse systems
- POS systems
- marketplaces
Common bottlenecks include:
- WordPress cron limitations
- plugin conflicts
- slow REST API processing
- object cache invalidation delays
Scaling often requires Redis object caching, async queues, and custom synchronization middleware.
SaaS billing platforms
Subscription systems synchronize:
- invoices
- usage records
- payment states
- refunds
Webhook reliability becomes critical here.
AI automation workflows
AI orchestration pipelines rely heavily on synchronization between:
- CRMs
- vector databases
- support systems
- automation engines
Missed updates create hallucinated context and unreliable automations.
Challenges of Syncing Data in Real-time
Real-time synchronization introduces operational overhead.
Common issues:
- distributed transaction handling
- schema mapping inconsistencies
- network latency
- deadlocks
- queue congestion
- infrastructure cost
Monolith architectures can simplify synchronization initially.
Microservices improve scalability later but increase synchronization complexity dramatically.
This trade-off is frequently underestimated.
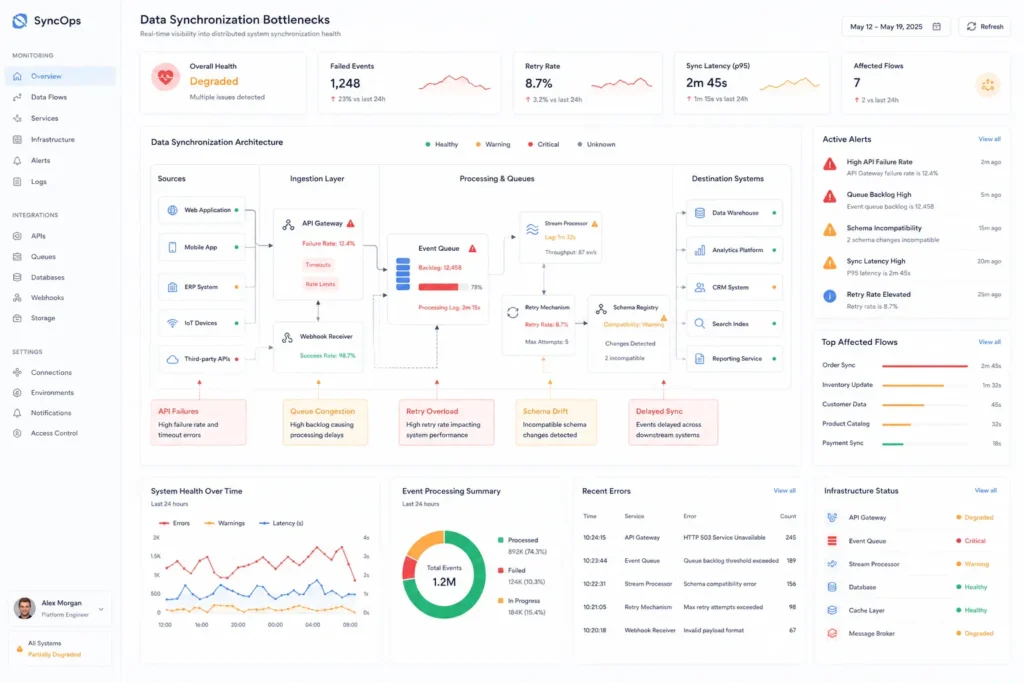
Optimizing data synchronization tools
Most businesses initially adopt generic database synchronization tools.
That works until:
- APIs become unreliable
- data volume spikes
- workflows become multi-directional
- audit requirements increase
Optimization priorities usually include:
- reducing data latency in database synchronization
- improving retry logic
- adding observability
- implementing dead-letter queues
- reducing unnecessary polling
- enforcing idempotency
Cheap synchronization setups become expensive operationally.
Best practices for data synchronization
Synchronization infrastructure requires ongoing monitoring, schema validation, retry management, and long-term website maintenance support to prevent operational drift as systems evolve.
Define an authoritative source
Every record needs ownership.
Without this, bidirectional synchronization becomes chaotic.
Use queues everywhere
Direct synchronous synchronization creates cascading failures.
Queues isolate systems operationally.
Track synchronization state
Maintain:
- timestamps
- event IDs
- version metadata
- reconciliation logs
Build for retries
Failures are normal in distributed environments.
Retries should never duplicate data records.
Add observability early
Monitoring should include:
- sync latency
- queue depth
- failure rates
- replay counts
- stale data detection
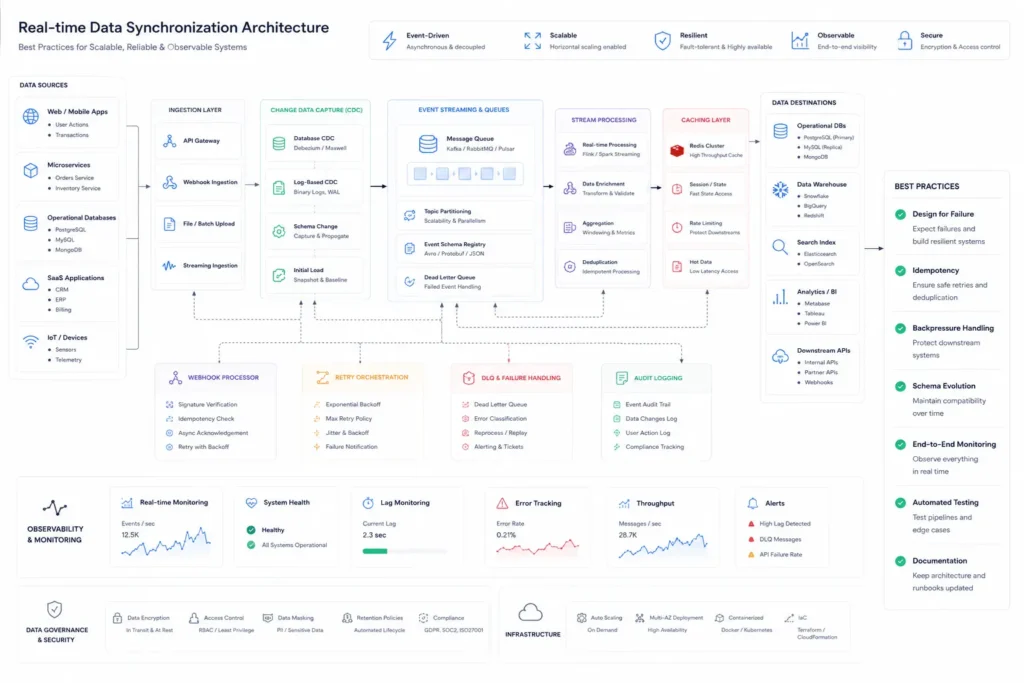
Key features to look for in a data sync platform
A serious data synchronization solution should support:
- CDC support
- event-driven architecture
- API integration
- webhook synchronization
- schema mapping
- RBAC and access controls
- audit trails
- encryption
- replay handling
- distributed scaling
- observability tooling
If a platform hides synchronization internals entirely, troubleshooting becomes painful later.
Operational transparency matters.
How to Choose the Right Real-time Data Synchronization Tool
The correct architecture depends on operational complexity.
Small WooCommerce stores may survive with lightweight webhook synchronization.
Enterprise SaaS platforms usually require:
- queue systems
- streaming infrastructure
- CDC pipelines
- custom middleware
- observability tooling
The wrong decision often comes from optimizing for development speed instead of long-term maintainability.
This becomes visible around scale thresholds:
- multiple regions
- 100k+ daily events
- multi-tenant workflows
- complex permissions
- AI automation layers
- marketplace integrations
That is usually where businesses start moving away from generic plugins toward custom synchronization architecture.
Filicode commonly sees this transition when companies outgrow disconnected SaaS tools, fragile WooCommerce plugins, or brittle API integrations that cannot handle operational scale reliably.
The architecture decisions made at this stage determine whether future growth creates operational leverage or operational chaos.
Benefits of data synchronization
When synchronization is engineered correctly, the impact is operationally measurable:
- fewer reconciliation tasks
- lower support overhead
- better analytics accuracy
- reduced inventory mismatches
- improved customer trust
- cleaner reporting consolidation
- better cross-team collaboration
Reliable synchronization reduces hidden operational friction across the organization.
That benefit compounds over time.
Frequently Asked Questions
What is database synchronization?
Database synchronization is the process of keeping multiple databases consistent by synchronizing inserts, updates, and deletions across systems.
What is real time data synchronization?
Real time data synchronization updates connected systems immediately after change events occur, minimizing latency and reducing stale data.
How to check database synchronization status in SQL Server?
For sql server database synchronization, teams commonly monitor replication health, CDC status, queue latency, transaction logs, and synchronization jobs using SQL Server Management Studio, replication monitors, or custom observability dashboards.
What are the best tools for real time data synchronization?
Popular tools for real time data synchronization include Kafka, Debezium, AWS DMS, RabbitMQ, Airbyte, Fivetran, and custom CDC pipelines depending on infrastructure requirements.
What causes synchronization failures?
The most common causes include API rate limits, schema drift, queue congestion, webhook delivery failures, duplicate events, and missing retry mechanisms.
Is bidirectional database synchronization risky?
Yes. Bidirectional database synchronization introduces conflict resolution complexity and requires strict ownership rules, versioning, and reconciliation logic.
Conclusion
Most synchronization problems do not appear during development.
They appear when:
- order volume increases
- integrations multiply
- teams depend on analytics accuracy
- operational workflows become distributed
- real-time updates become business-critical
That is where simplistic synchronization setups begin breaking down.
Frequent reconciliation work, stale dashboards, duplicate records, delayed inventory updates, and unreliable webhook pipelines are usually signs that the platform architecture is reaching its operational limits.
At that point, custom synchronization infrastructure, queue orchestration, event-driven systems, and scalable integration architecture become less of a technical upgrade and more of an operational necessity.
Businesses planning long-term growth should evaluate synchronization architecture early, before scaling problems become embedded into daily operations.